グラフ探索(BFS・DFS)とは|競技プログラミング初心者向けにわかりやすく解説
2026-04-24
代表講師 / カリキュラム監修
星出 遼汰郎(ほっしー)
中学生・高校生向けのプログラミング学習サービス「HaruCoder」を運営しています。指導歴は5年以上、これまでに100人以上の生徒を教えてきました。プログラミングの楽しさ、そして「考えることそのものの楽しさ」を伝えることを大切にしています。
グラフ探索とは
グラフ探索は、点(頂点)と線(辺)でつながった構造を、ある場所から順番にたどっていくアルゴリズムです。代表的な方法が、幅優先探索(BFS: Breadth-First Search)と深さ優先探索(DFS: Depth-First Search)の 2 つです。
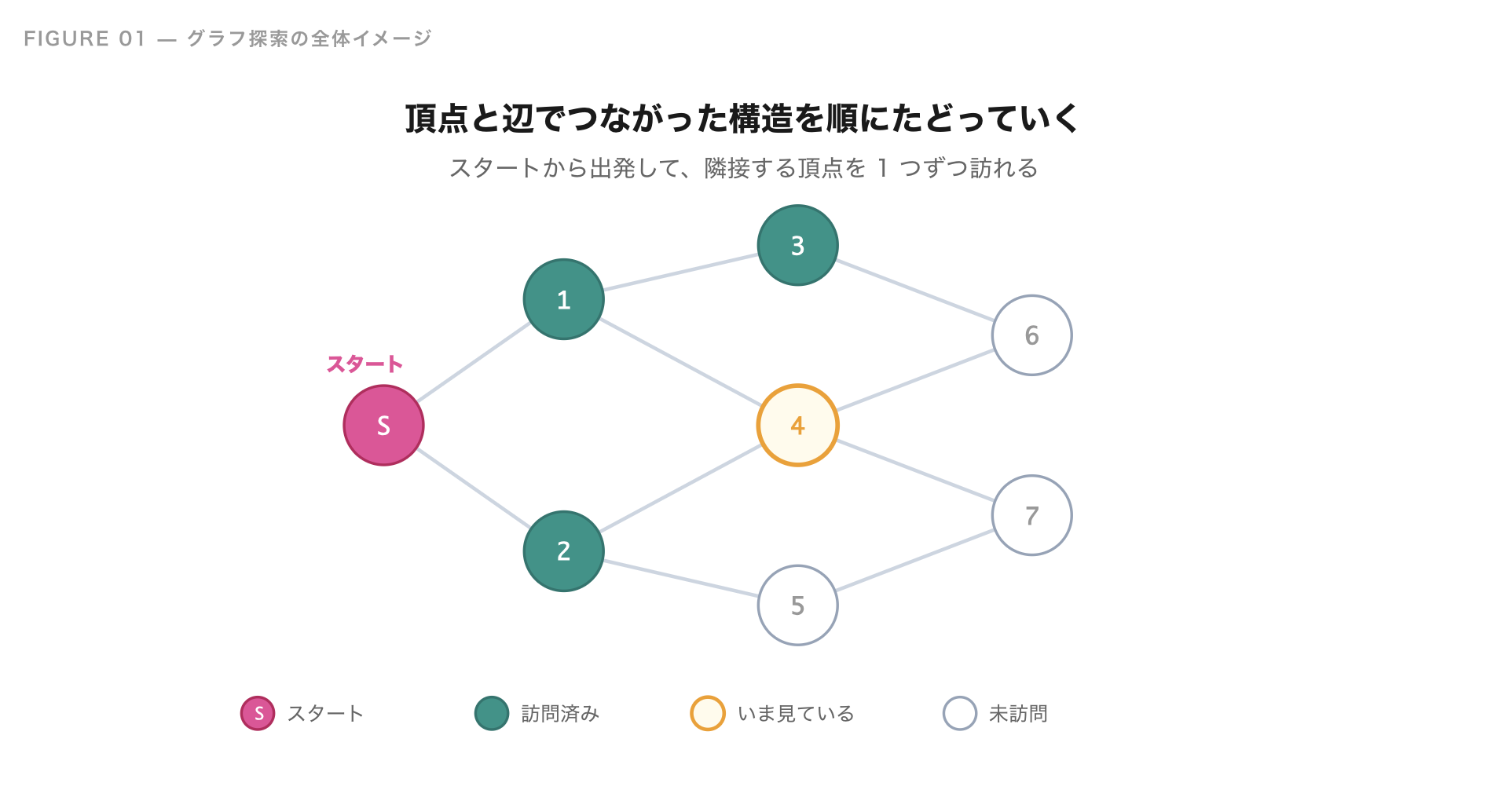
「グラフ」と聞くと棒グラフや折れ線グラフを思い浮かべるかもしれませんが、競技プログラミングでいうグラフは別物です。点(頂点)を 線(辺)でつないだ構造のことを指し、迷路、地図、SNS の友達関係、Webページのリンク構造など、世の中のいろいろなものがグラフで表せます。
JOI でも、迷路の最短経路を求める問題、連結成分(つながっている塊)の数を数える問題、経路を全部数え上げる問題など、グラフ探索を使う問題は本当によく出てきます。慣れるまでは難しく感じるかもしれませんが、BFS と DFS のどちらかを書ければ解ける問題も多いので、必ずマスターしておきたいアルゴリズムです。
まずはイメージから:迷路を探検する
グラフ探索の考え方は、次のような迷路を考えるとわかりやすいです。
マス目状の迷路があり、スタートからゴールまで行ける道を探したい。
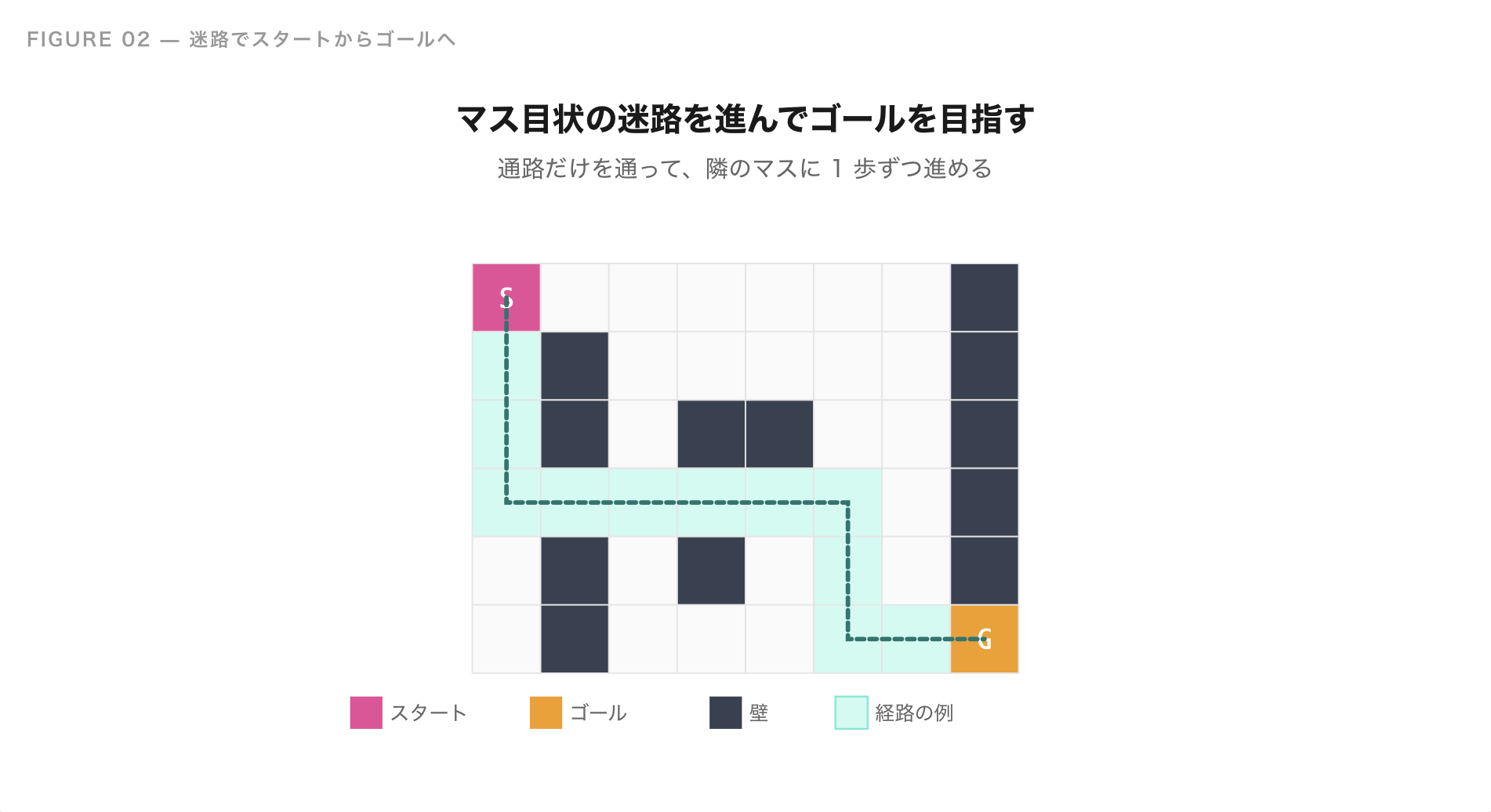
このとき、探し方には大きく 2 つの作戦があります。
作戦1:行けるところまで突き進む(DFS)
「とにかく一方向に進めるだけ進む。行き止まりに来たら、最後に分かれ道があったところまで戻って、別の道を試す」という作戦です。
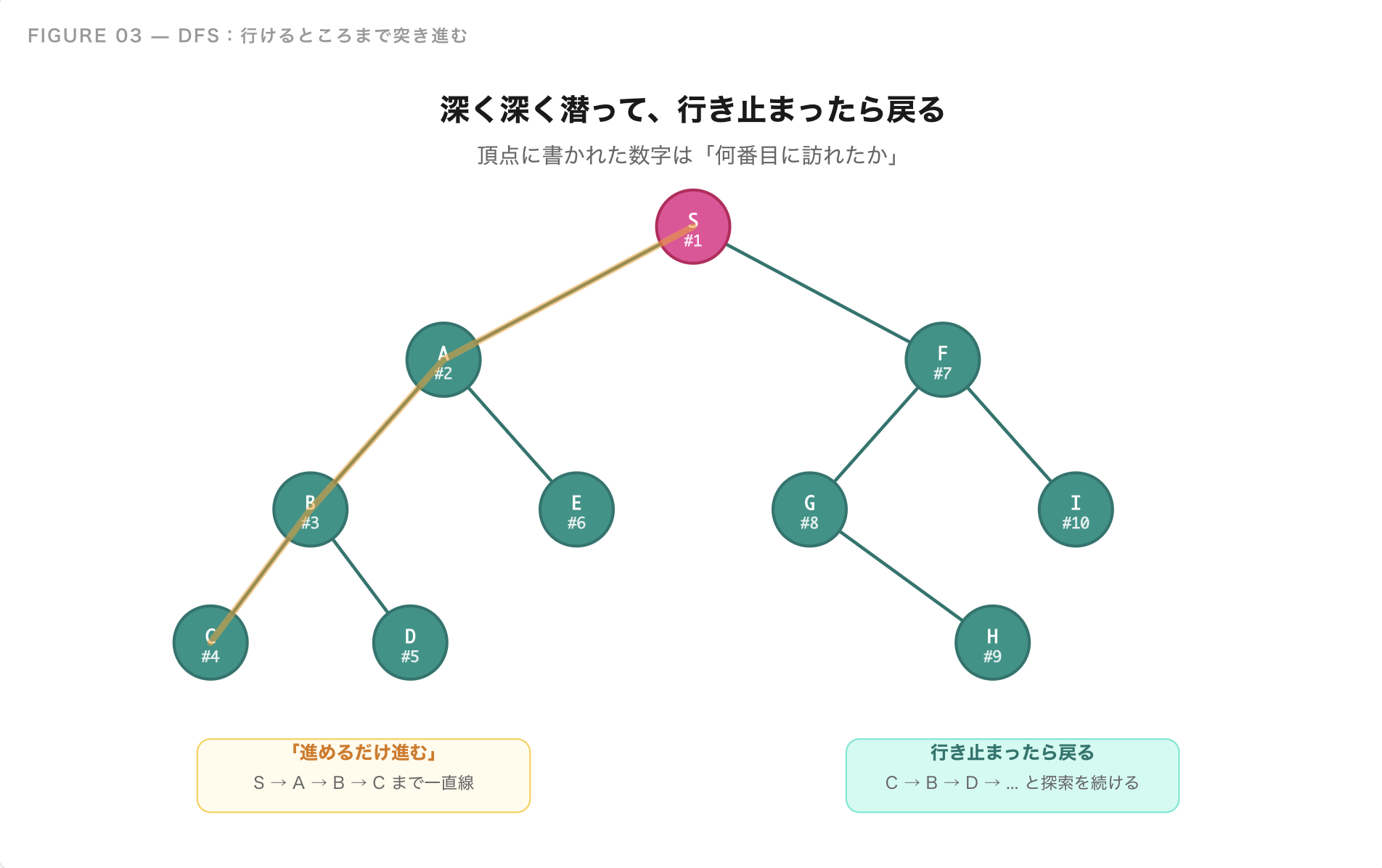
これが**深さ優先探索(DFS)**の考え方です。深く、深く潜っていって、ダメなら戻る。これだけのシンプルな作戦です。
作戦2:近いところから順に広げていく(BFS)
「スタートから 1 歩で行けるマスを全部見る。次に、2 歩で行けるマスを全部見る。次に 3 歩……」というふうに、距離が近い順にマスを開拓していく作戦です。
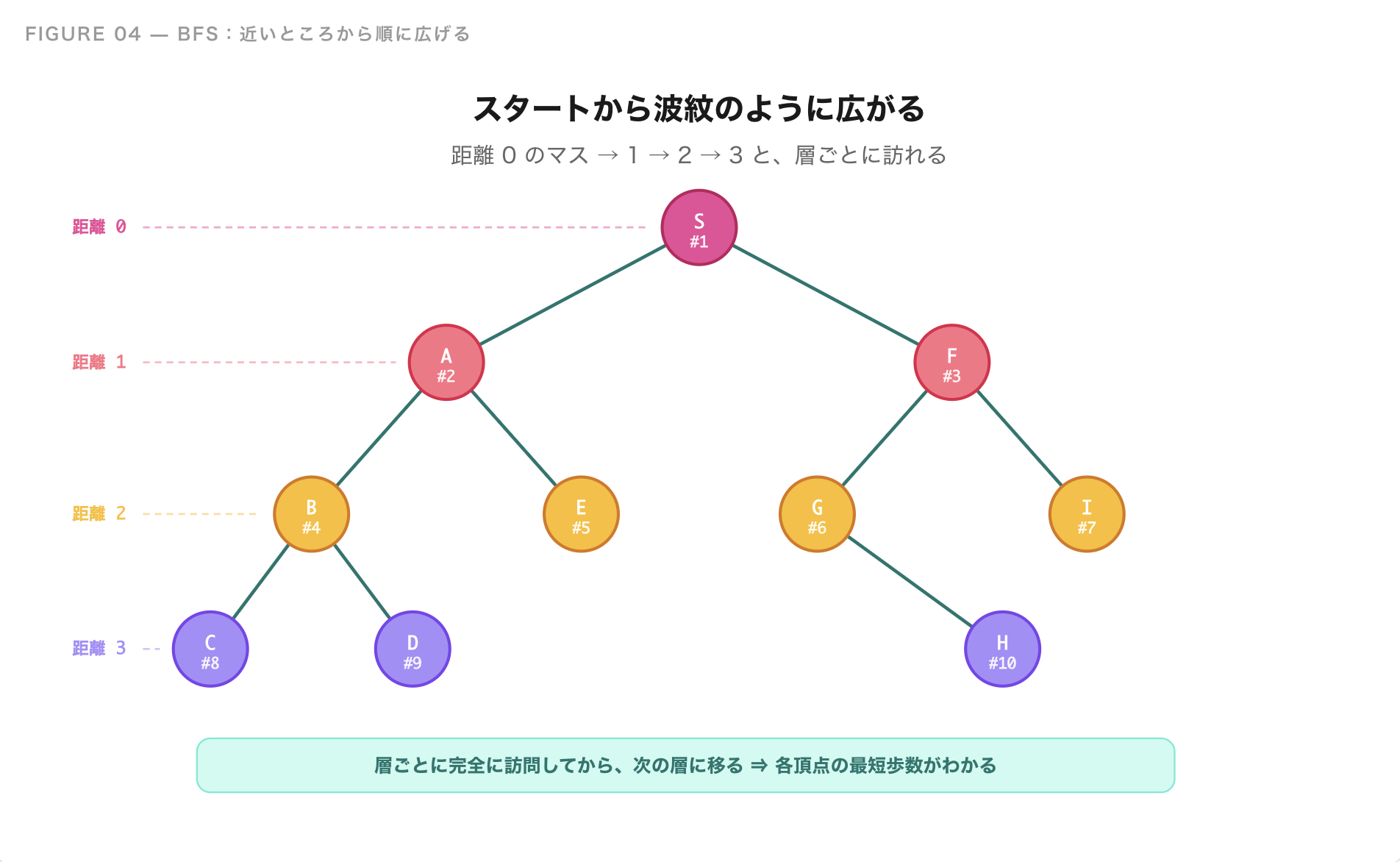
これが**幅優先探索(BFS)**の考え方です。スタートから波紋が広がるように、幅(横方向)に広く探していくイメージです。
どちらを使うかは問題によって変わりますが、「最短歩数を求めたい」なら BFS、「とにかく全部のマスを訪れたい」なら DFS、と覚えておくと最初は迷いません。
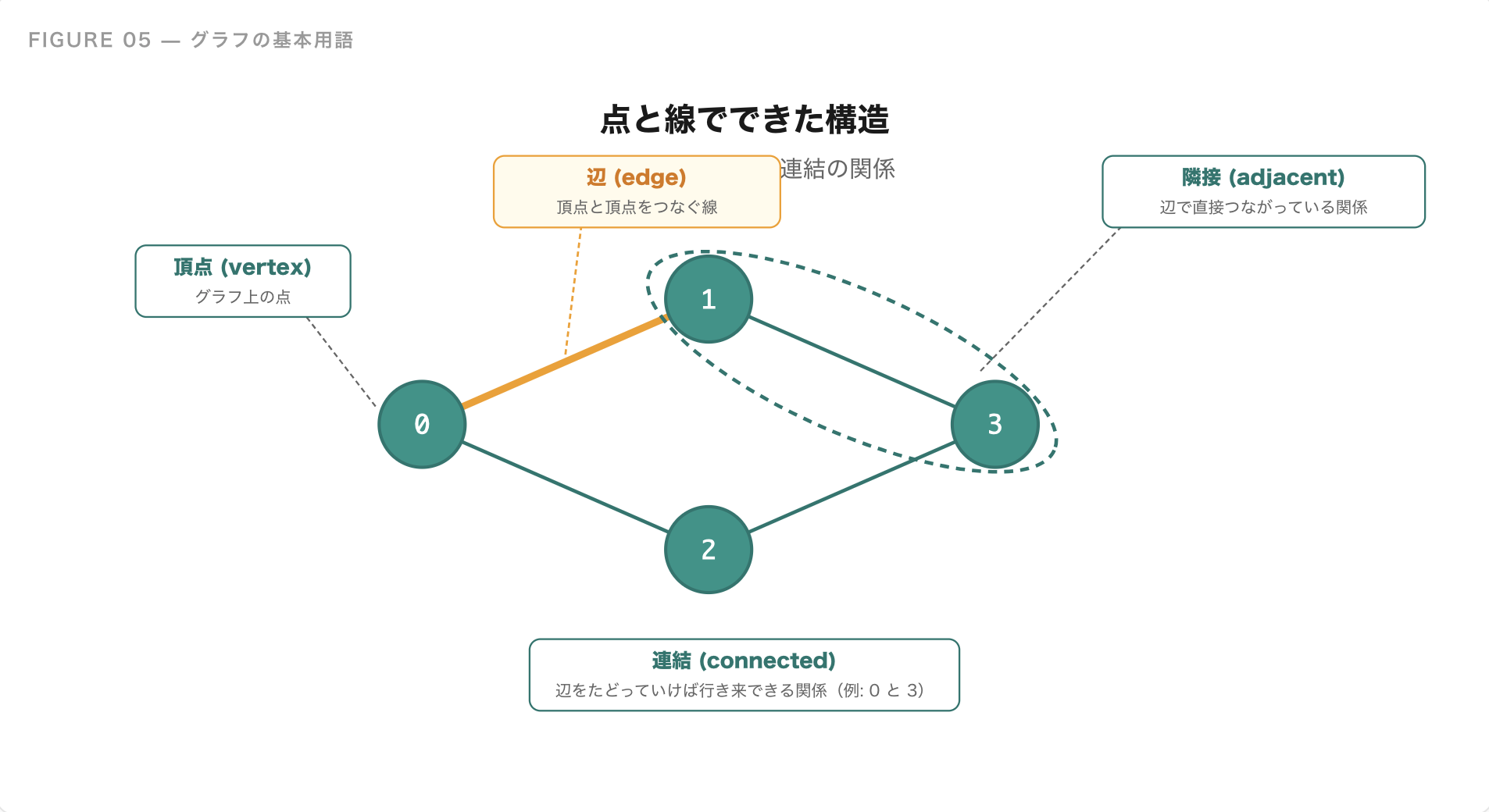
グラフの基本用語
実装に入る前に、グラフの基本用語を整理しておきましょう。
- 頂点(vertex / node):グラフ上の点。番号 0, 1, 2, ... で管理することが多い
- 辺(edge):頂点と頂点をつなぐ線
- 隣接(adjacent):辺で直接つながっている関係
- 連結(connected):辺をたどっていけば行ける関係
競技プログラミングでは、グラフを 隣接リスト という形で持つのが基本です。隣接リストは、ひとことで言うと 「各頂点ごとに、隣の頂点の番号を並べた 2 次元配列」 です。G[v] に「頂点 v から行ける頂点のリスト」を入れておきます。
例えば、次のような 5 つの頂点と 5 本の辺をもつ無向グラフを考えてみましょう。
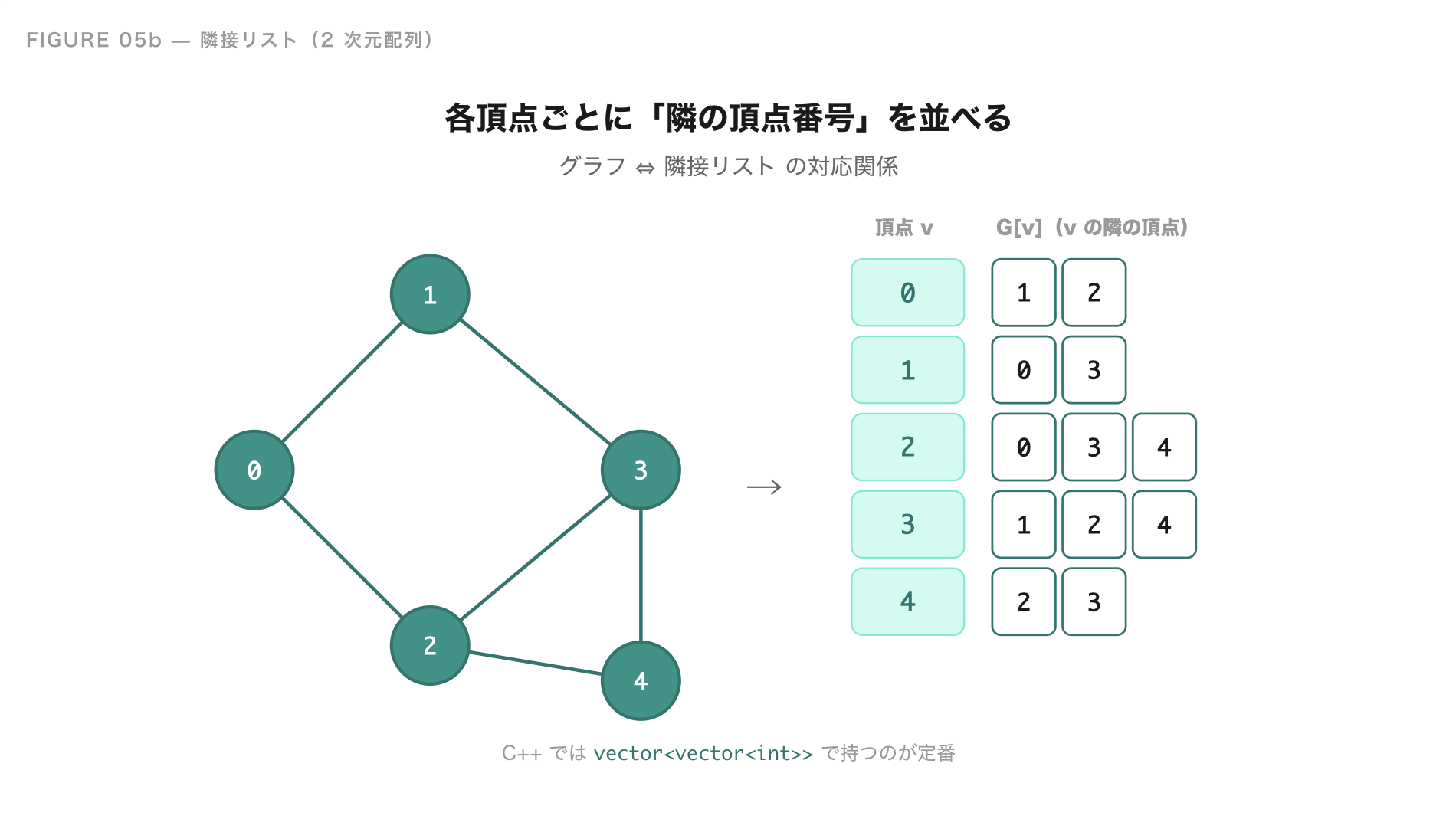
このグラフを隣接リストで表すと、こんなふうになります。
| 頂点 v | G[v](v の隣の頂点) |
|---|---|
| 0 | [1, 2] |
| 1 | [0, 3] |
| 2 | [0, 3, 4] |
| 3 | [1, 2, 4] |
| 4 | [2, 3] |
G 全体を見ると、「頂点番号 v」を行、「v の隣の頂点番号」を列にした 2 次元配列になっていることがわかります。各行の長さは頂点ごとに違っていてよく(その頂点の隣の数だけ要素を持つ)、C++ では vector<vector<int>> で表現するのが定番です。
// 頂点数 N、辺数 M のグラフを隣接リストで持つ
vector<vector<int>> G(N); // 2 次元配列:G[v] が頂点 v の隣のリスト
for (int i = 0; i < M; i++) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
G[b].push_back(a); // 無向グラフなら双方向に
}
これで、G[v] を for で回せば「頂点 v の隣の頂点」を全部見られます。グラフ探索のコードはほとんどこの形を前提にしていると思って大丈夫です。
深さ優先探索(DFS)の実装
DFS は、「今いる頂点の隣に、まだ訪れていない頂点があれば、そこへ進む。なければ戻る」というルールで動きます。
手順
- 現在地に「訪れた」マークを付ける
- 隣の頂点を 1 つ選ぶ
- その頂点がまだ未訪問なら、そこへ移動して 1 に戻る(再帰)
- 全ての隣を試したら、自分は終了して 1 つ前の頂点に戻る
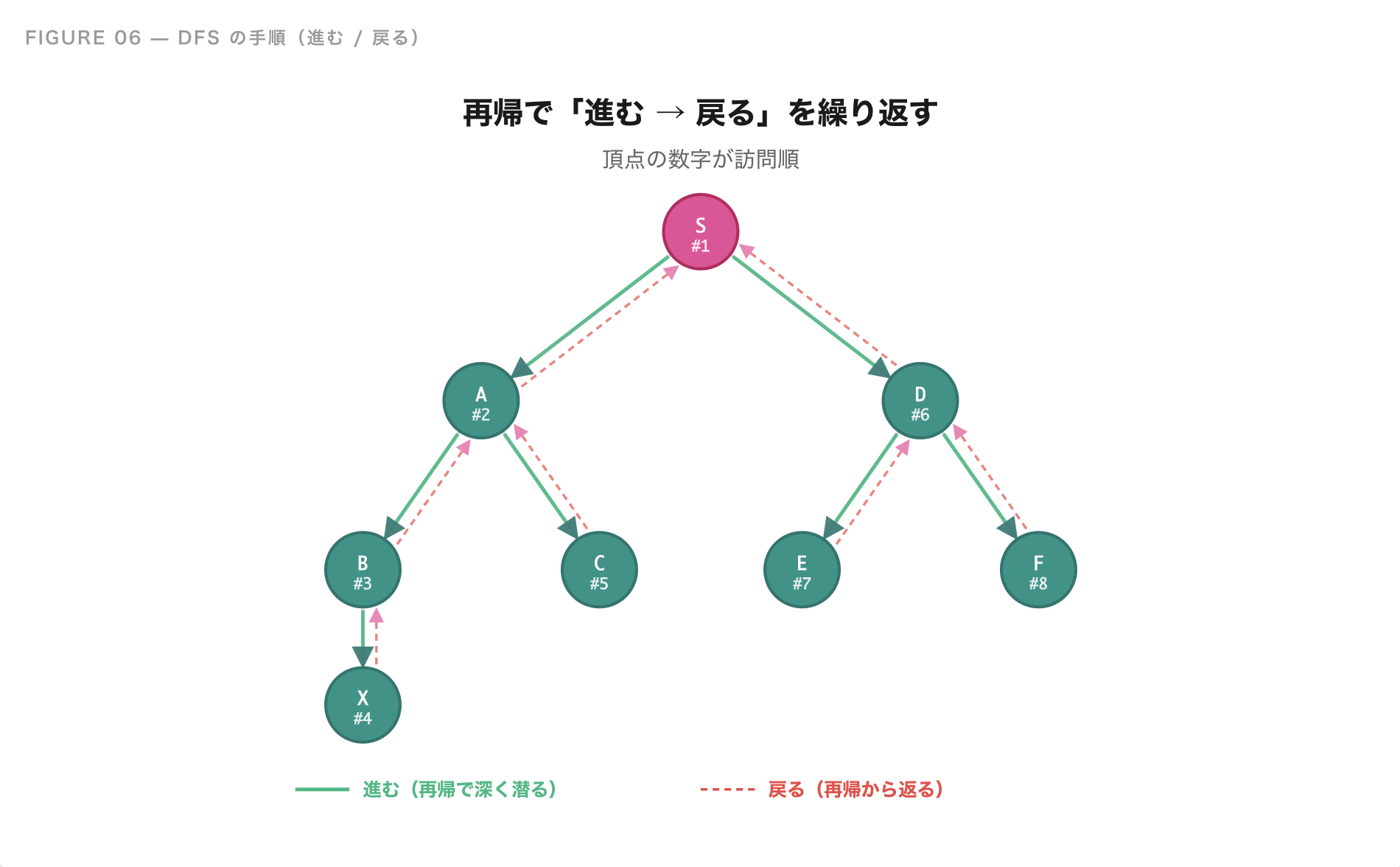
「進めるところまで進む → 戻る」という動きを、再帰関数で書くのが一番自然です。
C++ での実装
#include <iostream>
#include <vector>
using namespace std;
int N, M;
vector<vector<int>> G;
vector<bool> visited;
void dfs(int v) {
visited[v] = true; // 訪問済みにする
for (int next : G[v]) {
if (!visited[next]) {
dfs(next); // まだ訪れていなければ進む
}
}
}
int main() {
cin >> N >> M;
G.assign(N, {});
visited.assign(N, false);
for (int i = 0; i < M; i++) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
G[b].push_back(a);
}
dfs(0); // 頂点 0 からスタート
return 0;
}
ポイントは 2 つです。
visited配列で訪問済みかどうかを管理する(同じ頂点を 2 度訪れない)- 再帰関数で「隣の未訪問頂点に潜る」を繰り返す
これだけで、頂点 0 から行ける全頂点を訪れることができます。
幅優先探索(BFS)の実装
BFS は、「スタートから近い頂点から順に処理する」というルールで動きます。実装には キュー(queue) という、入れた順に取り出せるデータ構造を使います。
手順
- キューにスタート頂点を入れる。スタートの距離は 0
- キューから 1 つ頂点を取り出す
- その頂点の隣を順に見て、まだ未訪問ならキューに入れる(距離は今の頂点 + 1)
- キューが空になるまで 2-3 を繰り返す
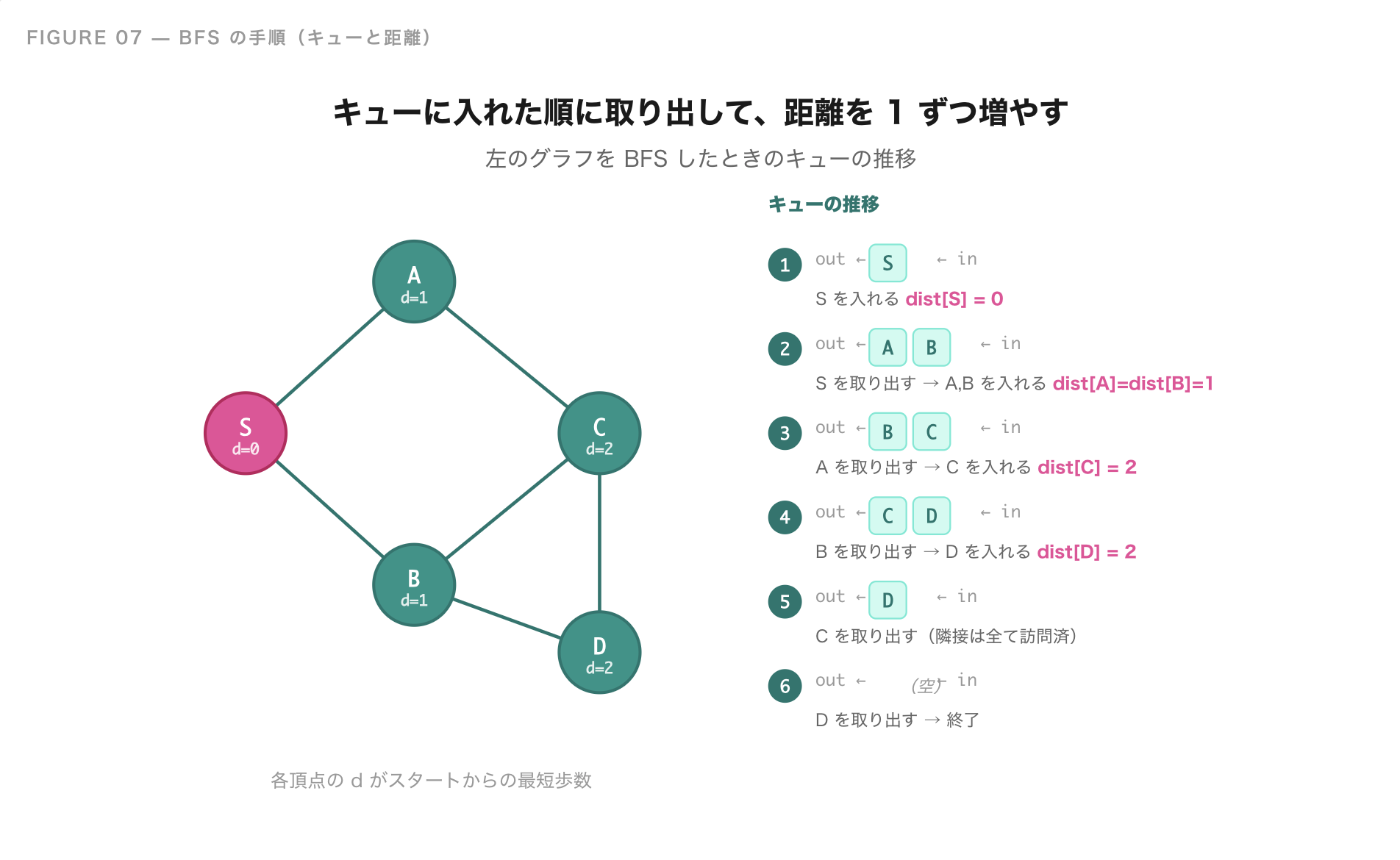
キューは「先入れ先出し(FIFO)」のデータ構造なので、スタートに近い頂点から順番に取り出されます。これが「波紋のように広がる」動きの正体です。
C++ での実装
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int main() {
int N, M;
cin >> N >> M;
vector<vector<int>> G(N);
for (int i = 0; i < M; i++) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
G[b].push_back(a);
}
// dist[v] = 頂点 0 から頂点 v までの最短歩数(未訪問なら -1)
vector<int> dist(N, -1);
queue<int> que;
dist[0] = 0;
que.push(0);
while (!que.empty()) {
int v = que.front();
que.pop();
for (int next : G[v]) {
if (dist[next] == -1) { // 未訪問なら
dist[next] = dist[v] + 1;
que.push(next);
}
}
}
// 各頂点までの最短距離を出力
for (int i = 0; i < N; i++) {
cout << "頂点 " << i << " まで " << dist[i] << " 歩" << endl;
}
return 0;
}
ポイントは 3 つです。
dist配列で「未訪問(-1)か、何歩で来たか」を管理する- キューに入れる時に距離を
dist[v] + 1で確定させる - キューが空になるまで取り出し続ける
BFS のすごいところは、これだけで**スタートから各頂点までの最短歩数(辺の重みが全部 1 のときの最短経路)**が一気に求まることです。迷路の最短経路問題は、ほぼこの形で解けます。
BFS と DFS の使い分け
「どっちを使えばいいの?」という疑問に対する目安は次のとおりです。
| やりたいこと | 向いているのは | 理由 |
|---|---|---|
| 最短歩数を求めたい | BFS | 近い順に見るので、最初に見つけた経路が最短 |
| 全部の頂点を訪れたい(連結成分) | どちらでも | 訪れる順番にこだわらないなら DFS が手軽 |
| 経路を全パターン数え上げたい | DFS | 「進む→戻る」と相性がよく、再帰で書きやすい |
| 木の中で何かを集計したい | DFS | 子→親と再帰的に値を集計できる |
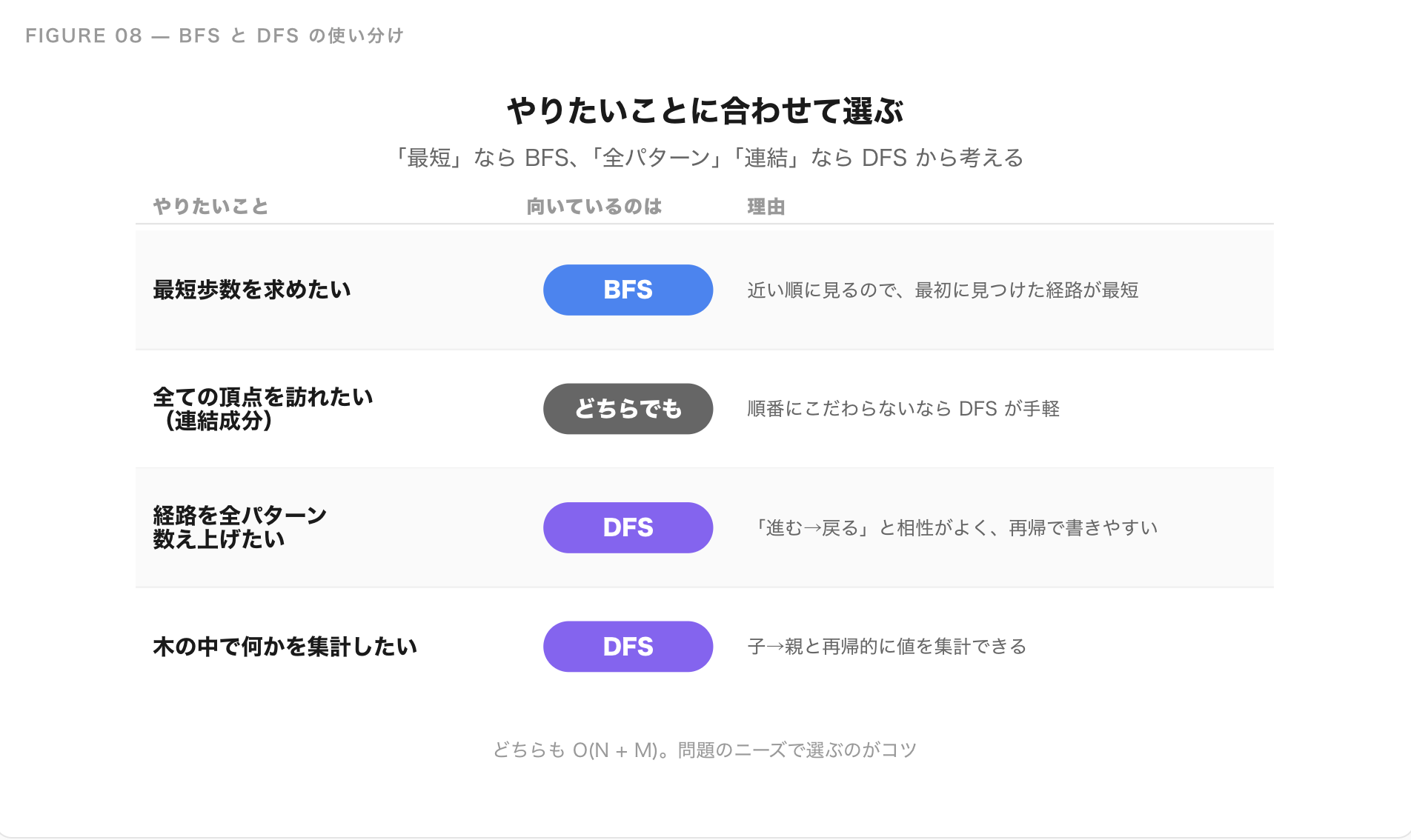
ざっくり言えば、「最短」と書いてあったら BFS、「全パターン」「連結」と書いてあったら DFS から考えると、迷う回数がぐっと減ります。
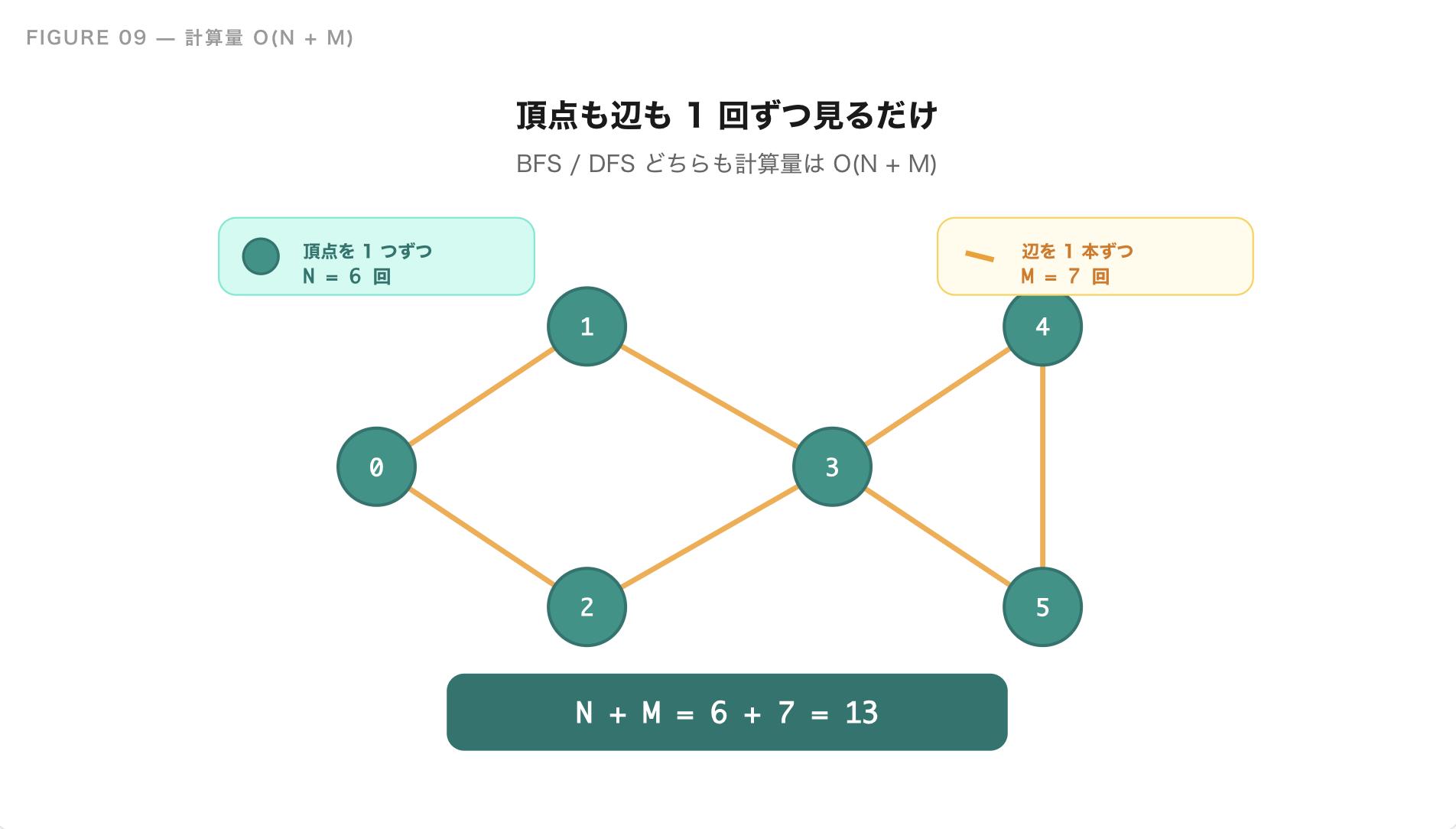
計算量
BFS と DFS は、どちらも全ての頂点と辺を 1 回ずつ見るだけで終わります。頂点数を N、辺数を M とすると、
計算量 = O(N + M)
です。
グラフ探索を使う典型問題としては、
- 迷路の最短歩数:マス目をグラフとみなして BFS する(JOI 一次予選・二次予選で頻出)
- 連結成分の個数:未訪問の頂点から DFS で塗りつぶし、塗りつぶした回数を数える
- 経路の数え上げ:DFS で「進む→戻る」を繰り返して全パターンを列挙する
- 木の DP:DFS で子から親へ値を集計していく
など、本当にたくさんあります。**「実際にこういう問題を解いてみたい!」**という方は、ぜひ記事末尾のHaruCoder の無料体験から挑戦してみてください。難易度順に問題が並んでいるので、段階的にレベルアップできます。
つまずきやすいポイント
1. visited の管理を忘れて無限ループ
訪問済みかどうかをチェックせずに進むと、同じ頂点を何度も訪れて永遠に終わらないことがあります。グラフ探索を書くときは、まず最初に visited 配列(または dist 配列)を用意するのを習慣にしましょう。
特に閉路(ループ)のあるグラフでは致命的です。木のように閉路がないと運良く動いてしまうこともありますが、油断は禁物です。
2. 再帰の深さが深すぎてスタックオーバーフロー
DFS を再帰関数で書くとき、頂点数が 10 万を超えるような大きなグラフだとスタックオーバーフローでクラッシュすることがあります。これは「再帰の呼び出し履歴を保存するメモ(スタック)」が足りなくなる現象です。
対策としては、
- スタックを自分で使って反復的に書く
- もしくは BFS(キュー)で代用する
という方法があります。最初のうちは、頂点数が大きい問題では BFS を選ぶのが安全です。
3. グラフが「無向」か「有向」かを読み間違える
問題によっては、辺が**一方通行(有向)**のこともあります。
- 無向グラフ:
G[a].push_back(b); G[b].push_back(a);(両方向に追加) - 有向グラフ:
G[a].push_back(b);(片方向のみ)
問題文の「a から b へ」「双方向に行き来できる」などの表現を必ず確認しましょう。間違えると、それだけで全テストケースが落ちます。
4. BFS で「キューに入れるタイミング」と「距離を確定するタイミング」を混同する
BFS では、キューに入れた瞬間に距離を確定します。「キューから取り出したときに距離を更新する」という書き方をすると、同じ頂点を何度もキューに入れてしまい、最短性が壊れることがあります。
// ✅ 正しい:キューに入れる時に dist を確定
if (dist[next] == -1) {
dist[next] = dist[v] + 1;
que.push(next);
}
これも定型文として体に染み込ませておきましょう。
まとめ
グラフ探索のポイントをもう一度整理しておきましょう。
- グラフは頂点と辺でできた構造で、**隣接リスト(2 次元配列)**で持つのが基本
- BFS(幅優先探索):キューを使い、近い頂点から順に見る → 最短歩数に強い
- DFS(深さ優先探索):再帰を使い、行けるところまで進む → 全列挙・連結成分に強い
- 計算量は両方とも O(N + M)。頂点・辺を 1 回ずつ見るだけで終わる
- 「最短」と書いてあったら BFS、「全パターン」「連結」なら DFS から考える
グラフ探索は、知っているだけでJOI で解ける問題が一気に増えるアルゴリズムです。一次予選・二次予選でも頻出なので、ぜひマスターしてください。
練習問題に挑戦しよう
アルゴリズムは「読んで理解した」だけでは使えるようになりません。実際に自分の手で書いて、問題を解くことで初めて身につきます。
HaruCoder のオンライン受講では、グラフ探索を使う問題を難易度順に用意しており、提出すれば自動で採点されます。「次に何を解けばいいかわからない」という悩みもなく、段階的にステップアップできます。
また、まだ競技プログラミングを始めたばかりで「そもそもどうやって問題を解くの?」という方は、先に以下の記事を読んでみてください。
- 競技プログラミングの始め方 — ブラウザだけで 1 問解く流れを画像付きで解説
- JOIの難易度全解説 — グラフ探索が実際に役立つコンテストの全体像
動的計画法(DP)とは|競技プログラミング初心者向けにわかりやすく解説
次の記事 (Part 6) →貪欲法(Greedy)とは|競技プログラミング初心者向けにわかりやすく解説
このシリーズの記事一覧
- 1全探索とは|競技プログラミング初心者向けにわかりやすく解説
- 2二分探索とは|競技プログラミング初心者向けにわかりやすく解説
- 3累積和とは|競技プログラミング初心者向けにわかりやすく解説
- 4動的計画法(DP)とは|競技プログラミング初心者向けにわかりやすく解説
- 5
グラフ探索(BFS・DFS)とは|競技プログラミング初心者向けにわかりやすく解説(今読んでいる記事)
- 6貪欲法(Greedy)とは|競技プログラミング初心者向けにわかりやすく解説
HaruCoderについて
中学生・高校生向けのオンライン競技プログラミング教室です。
情報オリンピック(JOI)一次予選突破率9割以上、AtCoder水色講師による個別指導。
月謝14,800円〜・入会金0円・オンライン全国対応。