全探索とは|競技プログラミング初心者向けにわかりやすく解説
2026-04-24
代表講師 / カリキュラム監修
星出 遼汰郎(ほっしー)
中学生・高校生向けのプログラミング学習サービス「HaruCoder」を運営しています。指導歴は5年以上、これまでに100人以上の生徒を教えてきました。プログラミングの楽しさ、そして「考えることそのものの楽しさ」を伝えることを大切にしています。
全探索とは
全探索(brute force)は、考えられるすべての候補を 1 つずつ試して、条件に合うものを見つけるアルゴリズムです。「しらみつぶし探索」とも呼ばれます。

工夫して効率的に解くのではなく、「とにかく全部試せば、いつか答えが見つかる」という、非常にシンプルな考え方です。
一見すると地味に見えますが、全探索は競技プログラミングで一番大事な考え方と言っても過言ではありません。なぜなら、
- 多くの問題は、まず全探索で解けるかどうかを考えるところから始まる
- より高度なアルゴリズム(二分探索・DP など)も、「全探索を速くしたもの」として理解するのが自然
だからです。「問題が出てきたら、まず全探索でどう解けるか考える」——これが競プロでの基本姿勢です。
まずはイメージから:鍵の組み合わせ
全探索の考え方は、次のような場面を想像するとわかりやすいです。
4 桁のダイヤル式の鍵があり、あなたは暗証番号を忘れてしまった。仕方がないので、0000 から 9999 まで順番に全部試してみることにした。

これはまさに全探索です。試す回数がある程度小さければ(具体的には、10,000,000回程度なら)十分高速に動作し、いつかは必ず正解にたどり着けるという強みがあります。
この例では、試す候補は 10000 通りです。パソコンなら 1 秒もかからずに全部チェックできます。このように「候補の数がそこまで多くないなら、全部試すのが一番シンプルで確実」——これが全探索の基本的な発想です。
基本パターン1:配列を全部見る
最もシンプルな全探索は、配列の要素を 1 つずつ順番にチェックするパターンです。
例:配列の最大値を求める
N 個の整数が並んだ配列 A の中から、最大値を求めよ。
これは「全部の要素を 1 回ずつ見る」ことで解けます。最大値を覚えておく変数を 1 つ用意して、配列を端から順にチェックし、より大きな値が出てきたら更新します。

C++ での実装
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N;
cin >> N;
vector<int> A(N);
for (int i = 0; i < N; i++) cin >> A[i];
int max_value = A[0]; // とりあえず最初の要素を最大と仮定
for (int i = 1; i < N; i++) {
if (A[i] > max_value) {
max_value = A[i]; // より大きな値が見つかったら更新
}
}
cout << max_value << endl;
return 0;
}
計算量は O(N) です。配列の要素を 1 回ずつしか見ないので、N が 100 万個あっても一瞬で答えが出ます。
この「配列を 1 周して条件に合うものを探す」パターンは、最大値・最小値・合計・平均・特定の値の探索など、本当にたくさんの場面で使います。全探索の基本中の基本なので、何も考えなくても書けるようになっておきましょう。
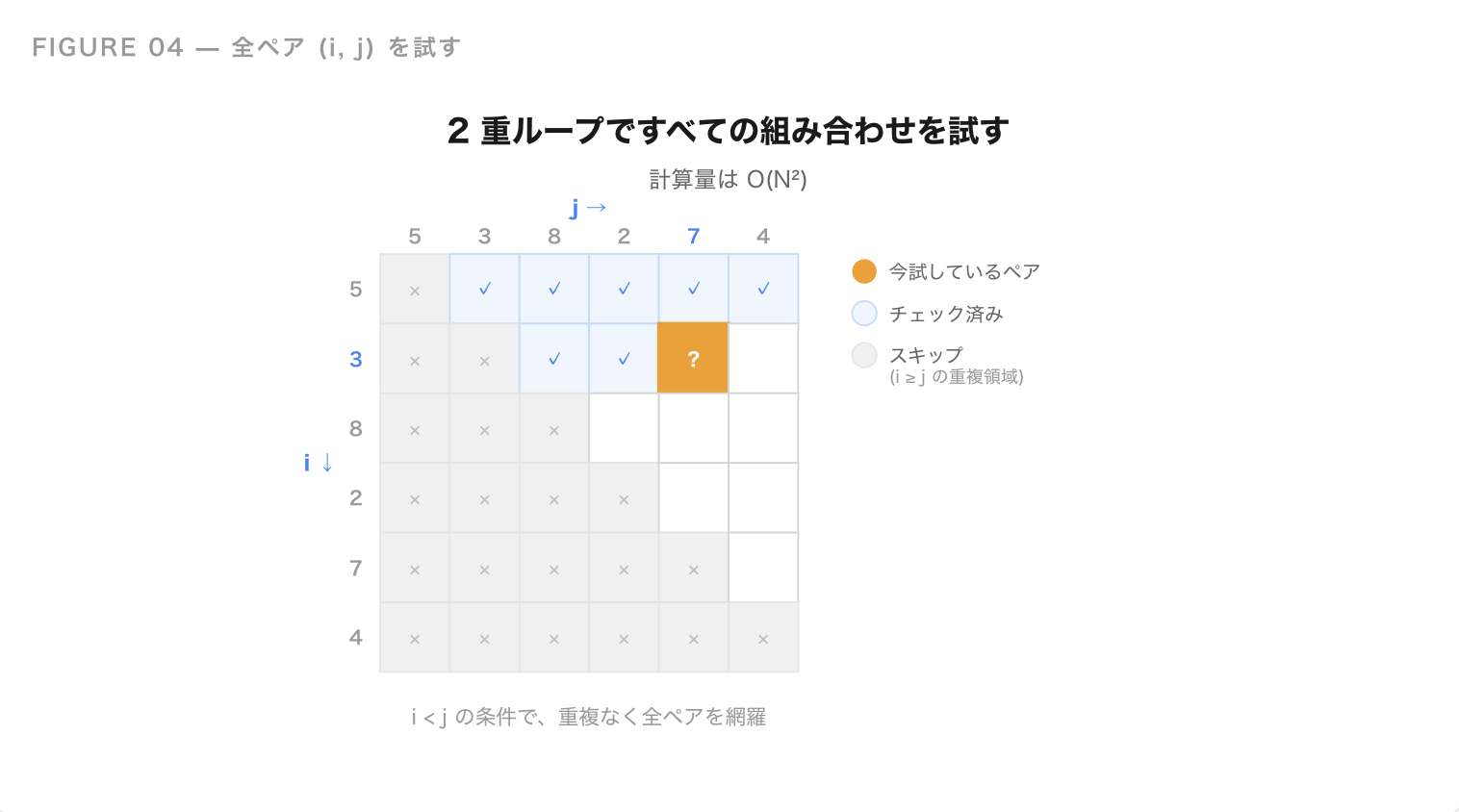
基本パターン2:全ペアを試す(2 重ループ)
次によく出てくるのが、2 つの要素の組み合わせを全部試すパターンです。
例:和が K になるペアを探す
N 個の整数 A[0], A[1], ..., A[N-1] がある。この中から 2 つを選んで和が K になる組み合わせが存在するか判定せよ。
すべての (i, j) のペアを試してみれば解けます。
C++ での実装
#include <iostream>
#include <vector>
using namespace std;
int main() {
// 入力
int N, K;
cin >> N >> K;
vector<int> A(N);
for (int i = 0; i < N; i++) cin >> A[i];
// 組み合わせを全探索
bool found = false;
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
if (A[i] + A[j] == K) {
found = true;
}
}
}
// 答えを表示
if(found){
cout << "Yes" << endl;
}
else{
cout << "No" << endl;
}
return 0;
}
ループが 2 重になっているので、計算量は O(N²) です。N = 1000 なら 100 万回で一瞬、N = 10000 なら 1 億回で数秒、N = 100000 なら 100 億回で間に合わなくなります。
ループの数が増えるほど、計算量は急激に増えるということは覚えておきましょう。
発展的な全探索
ここまでの「配列を 1 周する」「全ペアを試す」は、典型的な基本パターンでした。ここからは、もう一段工夫が必要な全探索を 3 つ紹介します。どれも JOI をはじめとする競技プログラミングで頻出のテクニックです。
3 重以上のループ:処理を関数に切り出そう
「3 つ選ぶ」問題なら 3 重ループで O(N³)、4 つなら O(N⁴)——というふうに、選ぶ個数を増やせばループの入れ子もどんどん深くなります。
ただ、ネストが深くなるほどコードは急激に読みにくくなります。特に、一番内側で判定処理や計算をそのまま書き始めると、全体として何をしているのか分からなくなりがちです。
// 読みにくい例:3 重ループの中に判定処理が埋まっている
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
for (int k = j + 1; k < N; k++) {
int sum = A[i] + A[j] + A[k];
bool ok = true;
// 他にも色々な条件チェックが続く……
if (ok && sum == K) {
// 見つかったときの処理
}
}
}
}
こういうときは、内側の処理を関数として切り出して名前を付けるのがオススメです。
// 3 つの要素が条件を満たすかを判定する関数
bool is_valid(int a, int b, int c) {
int sum = a + b + c;
// 判定処理
return sum == K;
}
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
for (int k = j + 1; k < N; k++) {
if (is_valid(A[i], A[j], A[k])) {
// 見つかったときの処理
}
}
}
}
こうすると、外側のループは「3 つの組み合わせを全部試している」という意図だけが一目で分かります。中身が気になれば is_valid を見に行けばいい、という構造です。ループのネストが深くても、「全探索の骨格」と「判定の中身」を分離すると、格段に読みやすくなります。
なお先ほど述べたように、3 重・4 重ループの計算量は O(N³)・O(N⁴) と急速に膨らみます。N が小さくないとすぐに時間切れになるので、そういう場合は「全探索以外のアルゴリズム」を検討することも必要になってきます。
bit 全探索
次に、「N 個のものから任意の個数を選ぶすべての組み合わせ」を試したいパターンです。
例:部分和問題
N 個の整数がある。この中からいくつかを選んで(1 つも選ばなくても、全部選んでも良い)、和が K になる選び方があるか判定せよ。
N 個それぞれについて「選ぶ/選ばない」の 2 通りがあるので、全部で 2ᴺ 通りの選び方があります。これをすべて試すのが bit 全探索です。

整数のビット(2 進数の各桁)を使うと、この 2ᴺ 通りをきれいに列挙できます。たとえば N = 3 なら、
| bit | 意味 |
|---|---|
000 (0) | どれも選ばない |
001 (1) | A[0] だけ選ぶ |
010 (2) | A[1] だけ選ぶ |
011 (3) | A[0] と A[1] を選ぶ |
100 (4) | A[2] だけ選ぶ |
101 (5) | A[0] と A[2] を選ぶ |
110 (6) | A[1] と A[2] を選ぶ |
111 (7) | 全部選ぶ |
というふうに、0 から 2ᴺ-1 までの整数が各アイテムの選び方に対応します。
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N, K;
cin >> N >> K;
vector<int> A(N);
for (int i = 0; i < N; i++) cin >> A[i];
bool found = false;
for (int bit = 0; bit < (1 << N); bit++) { // 2^N 通り
int sum = 0;
for (int i = 0; i < N; i++) {
if (bit & (1 << i)) { // i 番目のビットが立っていれば選ぶ
sum += A[i];
}
}
if (sum == K) found = true;
}
cout << (found ? "Yes" : "No") << endl;
return 0;
}
計算量は O(N × 2ᴺ) です。2ᴺ の部分が効いてくるので、N が 20 くらいまでなら現実的な時間で動きます。N = 20 なら 2²⁰ ≈ 100 万通り、N = 30 なら 2³⁰ ≈ 10 億通りで厳しくなってきます。
なお、上のコードに出てくる 1 << N や bit & (1 << i) の意味がピンとこない方、二進数やビット演算についての理解が曖昧な方は、先に プログラミング頻出概念!二進数とは? を読むと、bit 全探索のコードが一気に読み解けるようになります。
順列全探索(next_permutation)
最後は、N 個の要素の並べ方(順列)をすべて試すパターンです。
N 個の順列は N!(N の階乗)通りあります。N = 8 なら 8! = 40,320 通り、N = 10 なら 3,628,800 通りで、N ≤ 10 くらいまでなら全通り試せます。

例:巡回セールスマン問題
N 個の地点があり、地点 i から地点 j への移動コスト
d[i][j]が与えられる。地点 0 から出発してすべての地点を 1 度ずつ訪れ、地点 0 に戻るときの移動コストの合計を最小にせよ。
訪れる順番を全通り試せば解けます。C++ では next_permutation を使うと、順列を簡単に列挙できます。
#include <iostream>
#include <vector>
#include <algorithm>
#include <climits>
using namespace std;
int main() {
int N;
cin >> N;
vector<vector<int>> d(N, vector<int>(N));
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
cin >> d[i][j];
vector<int> order(N);
for (int i = 0; i < N; i++) order[i] = i; // {0, 1, 2, ..., N-1}
int ans = INT_MAX;
do {
int cost = 0;
for (int i = 0; i < N - 1; i++) {
cost += d[order[i]][order[i + 1]];
}
cost += d[order[N - 1]][order[0]]; // 最後の地点から 0 に戻る
ans = min(ans, cost);
} while (next_permutation(order.begin(), order.end()));
cout << ans << endl;
return 0;
}
ポイントは 2 つです。
next_permutationは「次の順列」を生成する関数。do { ... } while (next_permutation(...))の形で、ソート済み(昇順)の状態から始めて呼び出すと、すべての順列を 1 回ずつ列挙できる。- 計算量は O(N! × (1 回あたりの処理))。N = 10 くらいまでなら現実的だが、N = 15 だと 15! ≈ 1.3 兆通りで間に合わない。
並び順そのものが問題の本質に関わる場合(経路問題、割り当て問題、並べ替えの組み合わせなど)で、N が 10 以下なら、順列全探索が真っ先に候補になります。
全探索で解けるかの見分け方
「この問題、全探索で解ける?」を判断するには、問題に書かれている制約を見ます。一般的なパソコンは 1 秒間に約 10⁸ (1 億) 回の計算ができるので、この数を超えないかどうかが目安です。

よく使われる目安がこちらです。
| N の大きさ | 使える計算量 | 具体例 |
|---|---|---|
| N ≤ 20 | O(2ᴺ) | bit 全探索 |
| N ≤ 500 | O(N³) | 3 重ループの全探索 |
| N ≤ 5000 | O(N²) | 2 重ループの全探索 |
| N ≤ 10⁶ | O(N log N), O(N) | ソート、1 重ループ |
| N ≤ 10⁹ | O(log N) | 二分探索 |
つまり、問題に **「N ≤ 1000」と書かれていたら 2 重ループ(O(N²))の全探索が使える、「N ≤ 20」**と書かれていたら bit 全探索が使える、というふうに、制約から使えるアルゴリズムが透けて見えるのです。
これは競技プログラミングで最も大事なコツの一つです。問題を見たら、まず制約を確認しましょう。
つまずきやすいポイント
1. ループの範囲ミス
特に 2 重ループで「同じペアを 2 回数えてしまう」「自分自身とのペアを数えてしまう」といったミスがよくあります。
// ❌ 同じペアを 2 回数えてしまう
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) { ... }
}
// ✅ i < j のペアだけを数える
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) { ... }
}
問題によってどちらが正しいかは変わるので、何を数えているかを意識しましょう。
2. 計算量オーバー(TLE)
全探索は書きやすい一方で、計算量が膨らみやすいのが弱点です。先ほどの表を参考に、提出前に「このループは何回回るか?」を概算する習慣をつけましょう。
TLE(Time Limit Exceeded = 時間切れ)になった場合は、「全探索のままでは間に合わない → より賢いアルゴリズムが必要」というサインです。次の一手として、二分探索・累積和・DP などを検討することになります。
3. 答えを見つけたあともループを回し続ける
判定問題では、答えが見つかったら早めにループを抜ける(break)と速くなります。ただし、「すべての組み合わせを数える」問題では最後まで回す必要があります。問題文をよく読みましょう。
まとめ
全探索のポイントをもう一度整理しておきましょう。
- すべての候補を試す、最もシンプルで確実なアルゴリズム
- 配列を 1 周する O(N)、全ペアを試す O(N²)、部分集合を試す O(2ᴺ) が代表的なパターン
- 問題の制約を見れば、全探索で解けるかどうかの見当がつく
- まずは全探索で解けるか考える——これが競プロの基本姿勢
全探索は「泥臭い」方法に見えるかもしれませんが、頭の中で全探索の形に落とし込めるかは、そのまま競プロ力に直結します。もし全探索で間に合わないと分かったら、そこからどう高速化するかを考えていくのが次のステップです。
練習問題に挑戦しよう
アルゴリズムは「読んで理解した」だけでは使えるようになりません。実際に自分の手で書いて、問題を解くことで初めて身につきます。
HaruCoder のオンライン受講では、全探索を使う問題を難易度順に用意しており、提出すれば自動で採点されます。「次に何を解けばいいかわからない」という悩みもなく、段階的にステップアップできます。
また、まだ競技プログラミングを始めたばかりで「そもそもどうやって問題を解くの?」という方は、先に以下の記事を読んでみてください。
- 競技プログラミングの始め方 — ブラウザだけで 1 問解く流れを画像付きで解説
- JOIの難易度全解説 — 全探索が実際に役立つコンテストの全体像
このシリーズの記事一覧
- 1
全探索とは|競技プログラミング初心者向けにわかりやすく解説(今読んでいる記事)
- 2二分探索とは|競技プログラミング初心者向けにわかりやすく解説
- 3累積和とは|競技プログラミング初心者向けにわかりやすく解説
- 4動的計画法(DP)とは|競技プログラミング初心者向けにわかりやすく解説
- 5グラフ探索(BFS・DFS)とは|競技プログラミング初心者向けにわかりやすく解説
- 6貪欲法(Greedy)とは|競技プログラミング初心者向けにわかりやすく解説
HaruCoderについて
中学生・高校生向けのオンライン競技プログラミング教室です。
情報オリンピック(JOI)一次予選突破率9割以上、AtCoder水色講師による個別指導。
月謝14,800円〜・入会金0円・オンライン全国対応。