二分探索とは|競技プログラミング初心者向けにわかりやすく解説
2026-04-24
代表講師 / カリキュラム監修
星出 遼汰郎(ほっしー)
中学生・高校生向けのプログラミング学習サービス「HaruCoder」を運営しています。指導歴は5年以上、これまでに100人以上の生徒を教えてきました。プログラミングの楽しさ、そして「考えることそのものの楽しさ」を伝えることを大切にしています。
二分探索とは
二分探索(binary search)は、ソート済みのデータから目的の値を高速に見つけるアルゴリズムです。
「ソート済み」というのは、小さい順(または大きい順)に並んでいるという意味です。順番に並んでいるという性質を利用して、探す範囲を毎回半分ずつ狭めていくのが二分探索の核となるアイデアです。
何が嬉しいかというと、非常に速いことです。たとえばデータが 10 億個あっても、二分探索ならたった 30 回程度の比較で目的の値を見つけられます。全探索(しらみつぶし)なら 10 億回の比較が必要なので、その差は歴然です。
まずはイメージから:数当てゲーム
二分探索の考え方は、次のような「数当てゲーム」を考えるとわかりやすいです。
相手が 1 〜 100 のどれかの数を思い浮かべる。あなたは数を言って、相手から「もっと大きい」「もっと小さい」「正解」のヒントをもらいながら当てる。
このとき、どう聞くのが一番効率がいいでしょうか?
作戦1:1 から順番に聞く
「1?」「2?」「3?」…と順番に聞いていく作戦です。これは全探索と言われる方法で、最悪 100 回聞かないと当たりません。

作戦2:真ん中から聞く
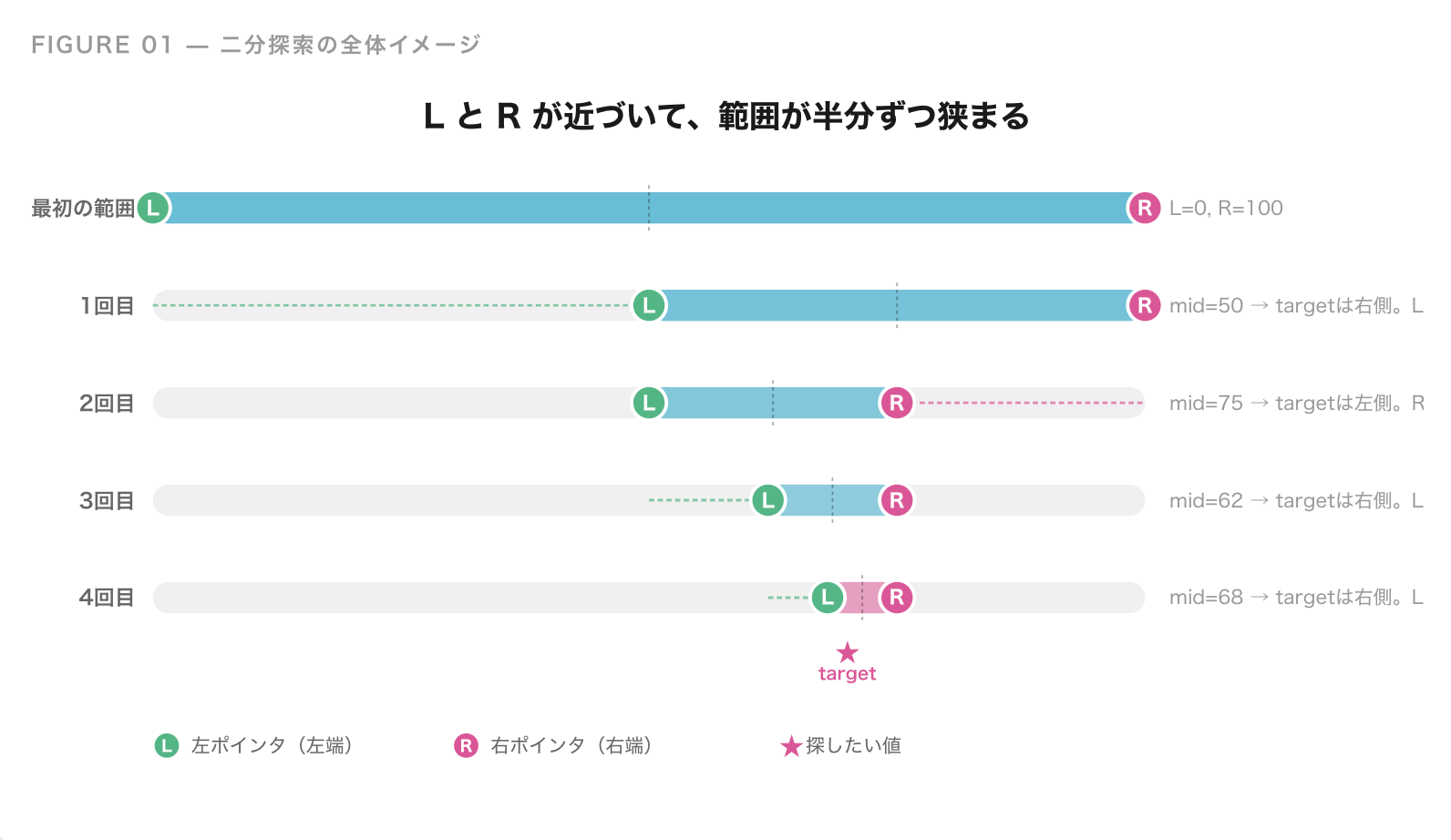
最初に「50?」と聞きます。すると次のどれかが返ってきます。
- 「もっと大きい」→ 答えは 51 〜 100 の範囲にある
- 「もっと小さい」→ 答えは 1 〜 49 の範囲にある
- 「正解」→ 終了

どちらのヒントでも、探す範囲が一瞬で半分になります。次はその範囲の真ん中を聞けば、さらに半分になります。これを繰り返すと、100 個から始めても 最大 7 回で必ず当てられます。
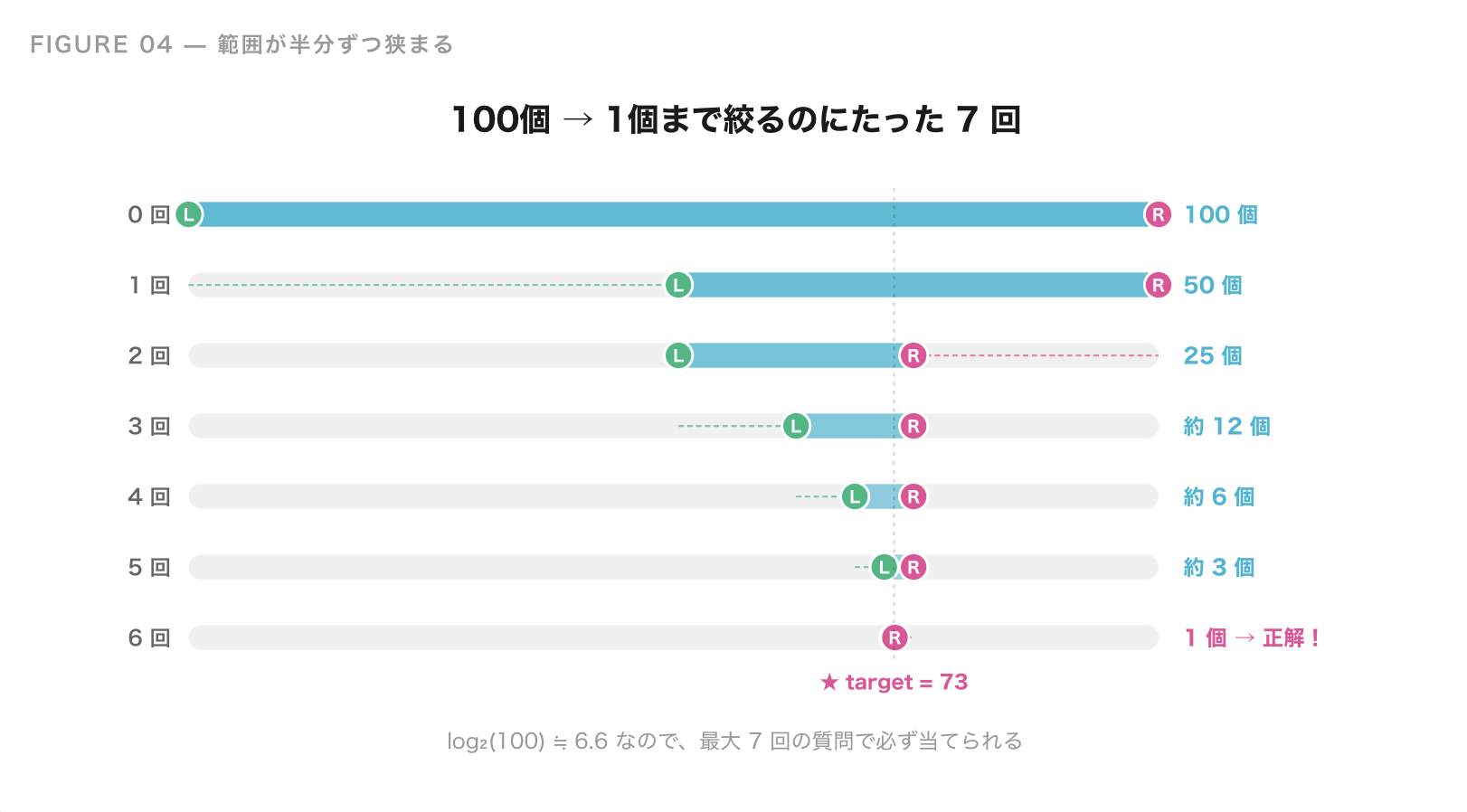
| 回数 | 残りの範囲 |
|---|---|
| 0 回 | 100 個 |
| 1 回 | 50 個 |
| 2 回 | 25 個 |
| 3 回 | 約 12 個 |
| 4 回 | 約 6 個 |
| 5 回 | 約 3 個 |
| 6 回 | 約 1 個 |
これが二分探索です。探す範囲を毎回半分にしていくので、途方もなく大きなデータでも少ない回数で目的の値にたどり着けます。
配列に対する二分探索
競技プログラミングでは、よくソート済みの配列から特定の値を探すという場面で二分探索を使います。
たとえば、次のようなソート済み配列があったとします。
A = [2, 5, 7, 11, 14, 18, 23, 29, 35, 42]
この中から 23 を探したいとしましょう。
手順
配列の左端を left、右端を right として、真ん中 mid を見ていきます。

- 初期値:
left = 0,right = 9(配列の要素数は 10 個) - 真ん中の位置
mid = (0 + 9) / 2 = 4を見る →A[4] = 14 - 探したい
23は14より大きい → 左半分は捨てる。left = 5 - 新しい
mid = (5 + 9) / 2 = 7→A[7] = 29 - 探したい
23は29より小さい → 右半分は捨てる。right = 6 - 新しい
mid = (5 + 6) / 2 = 5→A[5] = 18 - 探したい
23は18より大きい → 左半分は捨てる。left = 6 - 新しい
mid = (6 + 6) / 2 = 6→A[6] = 23→ 見つけた!
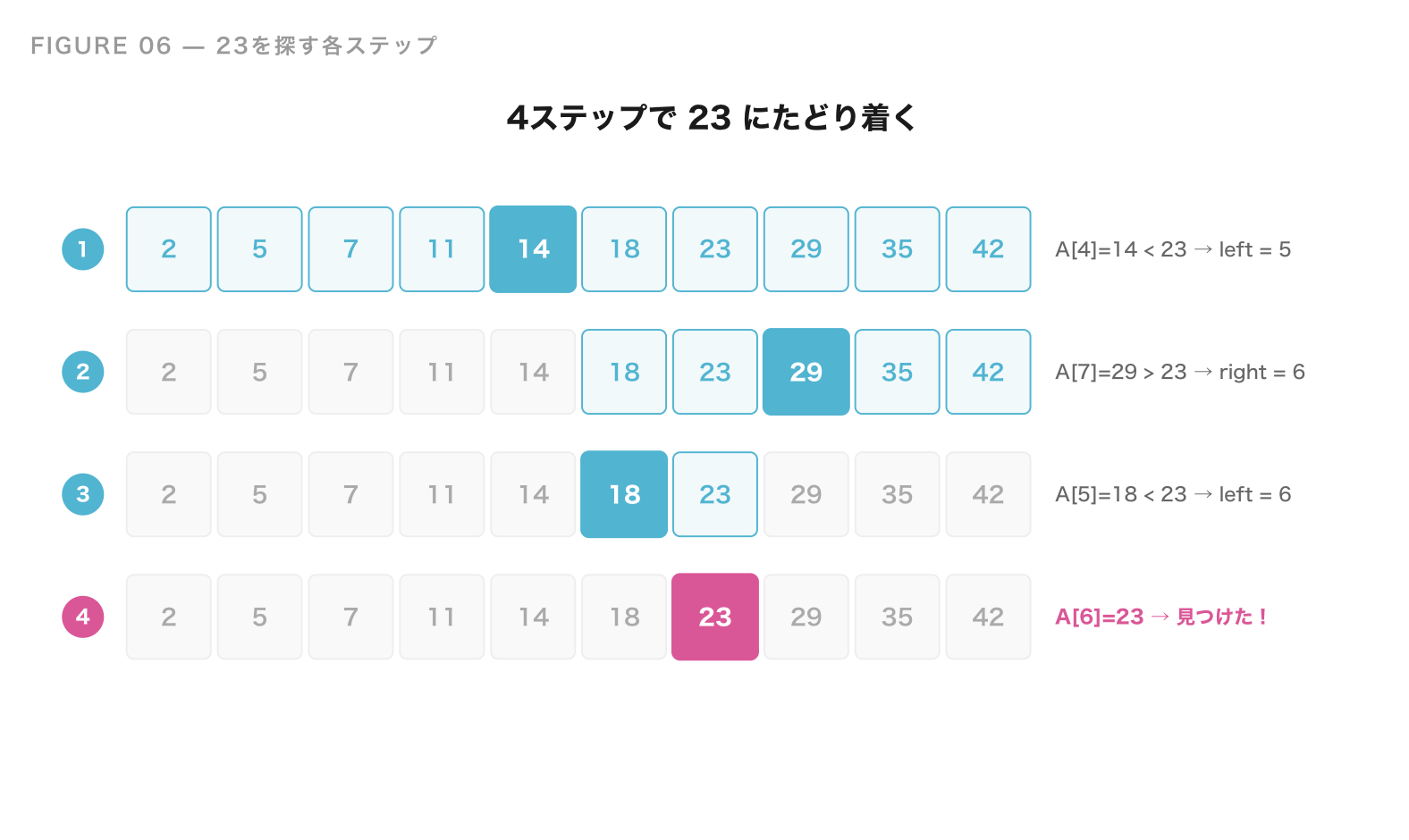
たった 4 回の比較で見つかりました。
C++ での実装
上の流れをそのままコードにすると、こうなります。
#include <iostream>
#include <vector>
using namespace std;
// ソート済み配列 A の中から target を探す
// 見つかればその位置(インデックス)、見つからなければ -1 を返す
int binary_search(const vector<int>& A, int target) {
int left = 0;
int right = A.size() - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (A[mid] == target) {
return mid; // 見つかった
} else if (A[mid] < target) {
left = mid + 1; // 右半分を探す
} else {
right = mid - 1; // 左半分を探す
}
}
return -1; // 見つからなかった
}
int main() {
vector<int> A = {2, 5, 7, 11, 14, 18, 23, 29, 35, 42};
cout << binary_search(A, 23) << endl; // 6
cout << binary_search(A, 100) << endl; // -1
return 0;
}
ポイントは 3 つだけです。
leftとrightで探索範囲を管理する- 真ん中
midとtargetを比較して、範囲を半分に狭める left > rightになったら終了(どこにもなかったということ)
C++ 標準ライブラリを使う方法
実は C++ には二分探索を行う標準ライブラリが用意されています。自分で書けるようになったら、本番ではこちらを使うのが便利です。
#include <algorithm>
#include <vector>
using namespace std;
int main() {
vector<int> A = {2, 5, 7, 11, 14, 18, 23, 29, 35, 42};
// 23 が存在するか
bool found = binary_search(A.begin(), A.end(), 23); // true
// 23 以上の値が最初に現れる位置
auto it1 = lower_bound(A.begin(), A.end(), 23);
int pos1 = it1 - A.begin(); // 6
// 23 より大きい値が最初に現れる位置
auto it2 = upper_bound(A.begin(), A.end(), 23);
int pos2 = it2 - A.begin(); // 7
}
特に lower_bound は競技プログラミングで非常によく使うので、名前だけでも覚えておきましょう。
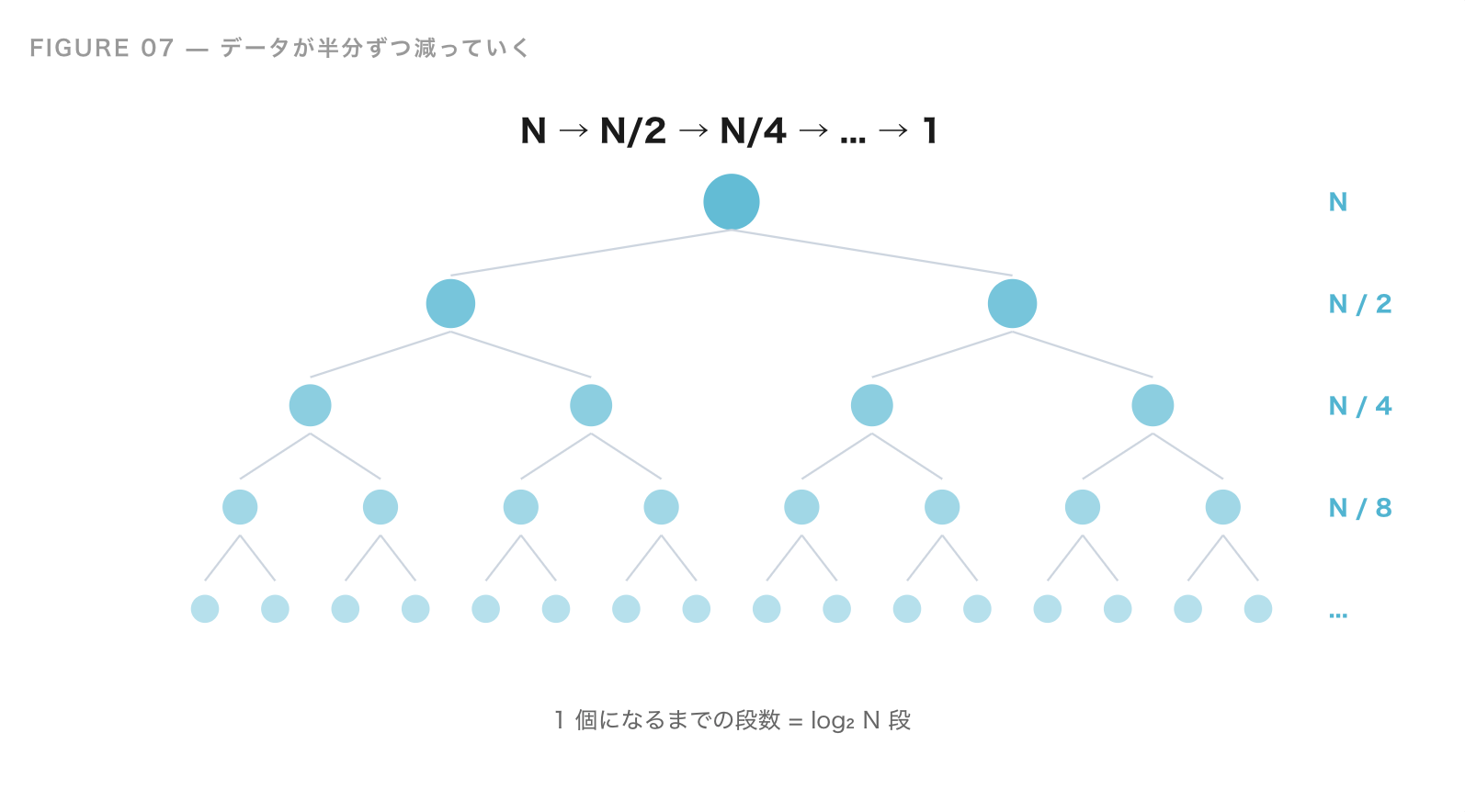
計算量:なぜこんなに速いのか
二分探索は、1 回の比較で探す範囲が半分になります。つまり、最初に N 個あったデータは、
N → N/2 → N/4 → N/8 → ... → 1
というふうに減っていきます。何回で 1 個まで減るかというと、これは log₂ N 回 です。
具体的な数字で見てみましょう。
| データ数 N | 全探索(O(N)) | 二分探索(O(log N)) |
|---|---|---|
| 100 | 100 回 | 約 7 回 |
| 10,000 | 10,000 回 | 約 14 回 |
| 1,000,000 | 100 万回 | 約 20 回 |
| 1,000,000,000 | 10 億回 | 約 30 回 |
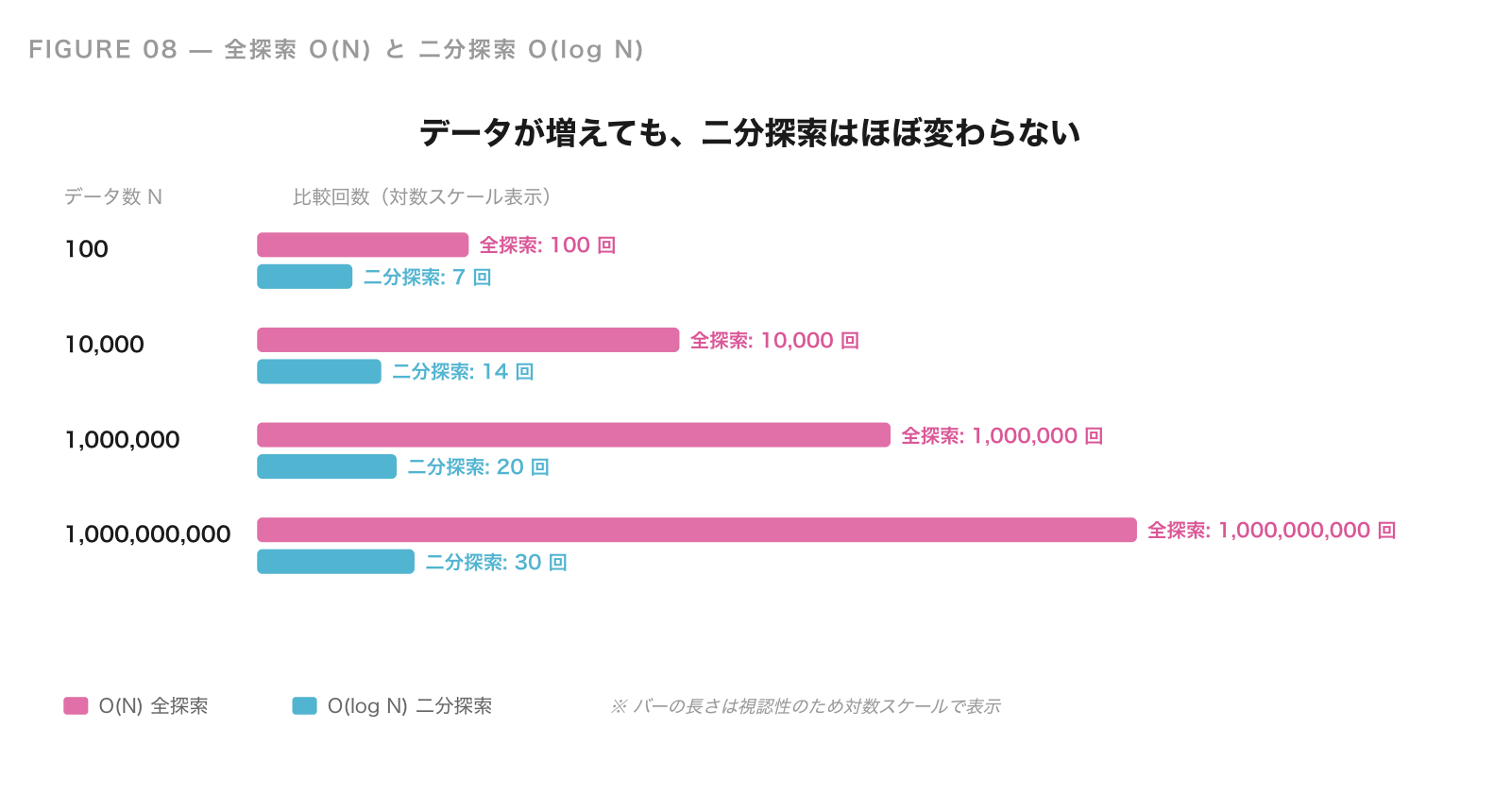
データが 1 万倍になっても、二分探索の比較回数はたった 10 回ちょっとしか増えないのです。これが「対数時間 O(log N)」の強さです。
応用:答えで二分探索する
ここまでは「配列の中から値を探す」という使い方を見てきましたが、二分探索はもっと広い場面で使えます。
代表的な応用が「答えで二分探索する」(めぐる式二分探索 とも呼ばれます)というテクニックです。「ある条件を満たす最大(最小)の値を求めよ」というタイプの問題で、答えの取りうる範囲そのものを二分探索することで、解ける問題の幅が一気に広がります。
考え方の詳細・典型問題・実装パターンを体系的に学びたい方は、ぜひ HaruCoder の無料体験 を覗いてみてください。難易度順の問題と自動採点で、二分探索の応用を段階的にマスターできます。
つまずきやすいポイント
1. 配列がソートされていないと使えない
二分探索はソート済みであることが大前提です。バラバラな配列に対してそのまま使うと正しい答えは出ません。ソートされていない場合は、まず sort でソートしてから使いましょう。
sort(A.begin(), A.end());
なお、ソート自体は O(N log N) かかるので、「1 回だけ探すなら全探索 O(N) の方が速い」という場合もあります。何度も探すときに二分探索は真価を発揮します。
2. mid の計算でオーバーフローに注意
int 型で (left + right) / 2 と書くと、left や right が大きいときに 足し算の途中でオーバーフローすることがあります。安全に書くなら次のどちらかを使います。
int mid = left + (right - left) / 2;
あるいは、そもそも long long を使う。競技プログラミングでは、配列の添字レベルなら問題ないことが多いですが、答えで二分探索するときに値の範囲が 10⁹ を超えるような場合は気をつけてください。
3. 無限ループに注意
範囲の更新を間違えると、永遠に終わらないループになります。例えば left = mid と書いてしまうと、left が更新されないケースがあり、そこで無限ループします。
基本形では、
A[mid] < targetのとき →left = mid + 1A[mid] > targetのとき →right = mid - 1
というふうに、必ず +1 か -1 を付けて動かすようにすると安全です。
まとめ
二分探索のポイントをもう一度整理しておきましょう。
- ソート済みデータから値を探すアルゴリズムで、探す範囲を毎回半分に狭める
- 計算量は O(log N)。10 億個のデータでも 30 回程度で探し終わる
- C++ では
lower_bound/upper_bound/binary_searchが標準で使える - 「答えで二分探索する」応用パターンを覚えると、解ける問題の幅が一気に広がる
二分探索は、知っているだけで解ける問題が劇的に増えるアルゴリズムです。JOI 一次予選・二次予選でも頻出なので、ぜひマスターしてください。
練習問題に挑戦しよう
アルゴリズムは「読んで理解した」だけでは使えるようになりません。実際に自分の手で書いて、問題を解くことで初めて身につきます。
HaruCoder のオンライン受講では、二分探索を使う問題を難易度順に用意しており、提出すれば自動で採点されます。「次に何を解けばいいかわからない」という悩みもなく、段階的にステップアップできます。
また、まだ競技プログラミングを始めたばかりで「そもそもどうやって問題を解くの?」という方は、先に以下の記事を読んでみてください。
- 競技プログラミングの始め方 — ブラウザだけで 1 問解く流れを画像付きで解説
- JOIの難易度全解説 — 二分探索が実際に役立つコンテストの全体像
このシリーズの記事一覧
- 1全探索とは|競技プログラミング初心者向けにわかりやすく解説
- 2
二分探索とは|競技プログラミング初心者向けにわかりやすく解説(今読んでいる記事)
- 3累積和とは|競技プログラミング初心者向けにわかりやすく解説
- 4動的計画法(DP)とは|競技プログラミング初心者向けにわかりやすく解説
- 5グラフ探索(BFS・DFS)とは|競技プログラミング初心者向けにわかりやすく解説
- 6貪欲法(Greedy)とは|競技プログラミング初心者向けにわかりやすく解説
HaruCoderについて
中学生・高校生向けのオンライン競技プログラミング教室です。
情報オリンピック(JOI)一次予選突破率9割以上、AtCoder水色講師による個別指導。
月謝14,800円〜・入会金0円・オンライン全国対応。